Construyendo una plataforma Big Data open-source desde cero (I): Persistencia

Hay muchos motivos por los que se puede necesitar una plataforma de Big Data: desde analizar y producir conocimiento a partir de datos procedentes del negocio, hasta crear modelos de inteligencia artificial a partir de textos o imágenes. Los datos que se almacenarán, en cada caso, son distintos. Los flujos de análisis, los procesos de limpieza y preparación, y las herramientas que se utilizarán, también.
En esta serie de entradas al blog nos proponemos construir una plataforma de Big Data de propósito general a partir de soluciones open-source. Sentaremos unos cimientos que podrán ser compartidos por proyectos heterogéneos, y añadiremos algunas herramientas específicas para casos de uso concretos. Además, la plataforma que presentamos podrá desplegarse tanto en infraestructuras cloud como on-premise. A lo largo de estos posts, además de explicar los motivos que nos han llevado a escoger cada una de las herramientas, intentaremos dar algunas nociones básicas sobre ellas: cómo funcionan, qué formatos utilizan, etcétera. Además, en Github tenemos un repositorio en el que explicamos cómo desplegar la plataforma y damos ejemplos de uso.
Cualquier plataforma de Big Data en la actualidad, debido a sus exigencias en cuanto a capacidad de almacenamiento —en el orden de los petabytes— y de procesamiento —imposibles sin ejecución en paralelo—, requiere de un entorno distribuido. En este sentido, hemos escogido Kubernetes como framework para desplegar sistemas distribuidos de forma robusta y a partir de contenedores. Kubernetes es el estándar de facto en la gestión de contenedores a escala, y todas las grandes plataformas cloud lo ofrecen como servicio.
El hecho de trabajar con Kubernetes guiará algunas de las elecciones que tomemos posteriormente ya que, en igualdad de condiciones, optaremos por soluciones que sean nativas de Kubernetes. Es el caso de las dos primeras herramientas que presentamos en las dos primeras entregas: MinIO como sistema de almacenamiento, y Argo Workflows como gestor de flujos de trabajo.
Almacenamiento a gran escala: MinIO
El término Big Data implica cantidades ingentes de datos, muchas veces en el orden de los petabytes. Estos datos pueden ser estructurados, como los que tradicionalmente se almacenan en bases de datos, o no estructurados, es decir, imágenes, texto, vídeos, etc. ¿Podemos contar con una única solución de almacenamiento compatible con ambos?
Al comienzo de un proyecto de Big Data no siempre está claro cuáles serán las cantidades de datos que se manejarán a corto, medio y largo plazo. Por ello, es importante contar con un sistema fácilmente escalable.
También es crucial poder encontrar los datos guardados. Aunque pueda parecer obvio, este es, precisamente, uno de los grandes problemas de los data lakes en los que se vierte todo tipo de información sin una organización adecuada. Acaban convirtiéndose en data swamps, pantanos de los que resulta muy difícil obtener valor porque es imposible de recuperar información útil. En otro post hablaremos de tecnologías de data governance y data discovery, que nos permitirán aliviar este problema en el caso de los datos estructurados. Pero, ¿qué hay del caso de los datos no estructurados (imágenes, texto), para los cuales este problema es especialmente agudo?
Por último, es imperativo poder garantizar la integridad de los datos. ¿Contaremos con copias de seguridad? ¿Serán eficientes en cuanto al espacio que ocupan? ¿Podremos almacenar distintas versiones de los archivos guardados?
El almacenamiento de objetos es un paradigma de almacenamiento diseñado para el mundo cloud, es decir, distribuido y escalable, y nos da soluciones a los problemas que acabamos de mencionar. ¿En qué consiste el almacenamiento de objetos? ¿Qué significa “objeto” en este caso?
Un objeto no es más que el archivo que deseamos almacenar acompañado de metadatos -relativos tanto a su contenido como a su uso- y asociado a un identificador único. Una parte importante de los metadatos serán las etiquetas descriptivas, escogidas intencionalmente para facilitar su posterior recuperación. Cuantas más etiquetas asociemos a los archivos, más caminos generaremos para hallarlos en el futuro.
El exponente más conocido de este tipo de servicio es Amazon S3. Sin embargo, Amazon S3 no está disponible en entornos on-premise y por este motivo hemos buscado alternativas como MinIO. MinIO es un software de almacenamiento de objetos open source y completamente compatible con la API de S3. Fue diseñado para ser integrarse nativamente con Kubernetes y puede instalarse en la nube pública y la nube privada (y es más rápido que S3).
En un entorno on-premise, aumentar su capacidad de almacenamiento es tan fácil como añadir nodos a Kubernetes. MinIO utiliza local persistent volumes para agilizar la comunicación entre la aplicación y el disco y, gracias a DirectPV, se encarga de localizar los discos, formatearlos y monitorizarlos. Con MinIO se facilita la gestión del almacenamiento y se elimina la necesidad de utilizar sistemas SAN o NAS.
Un sistema de réplicas muy eficiente
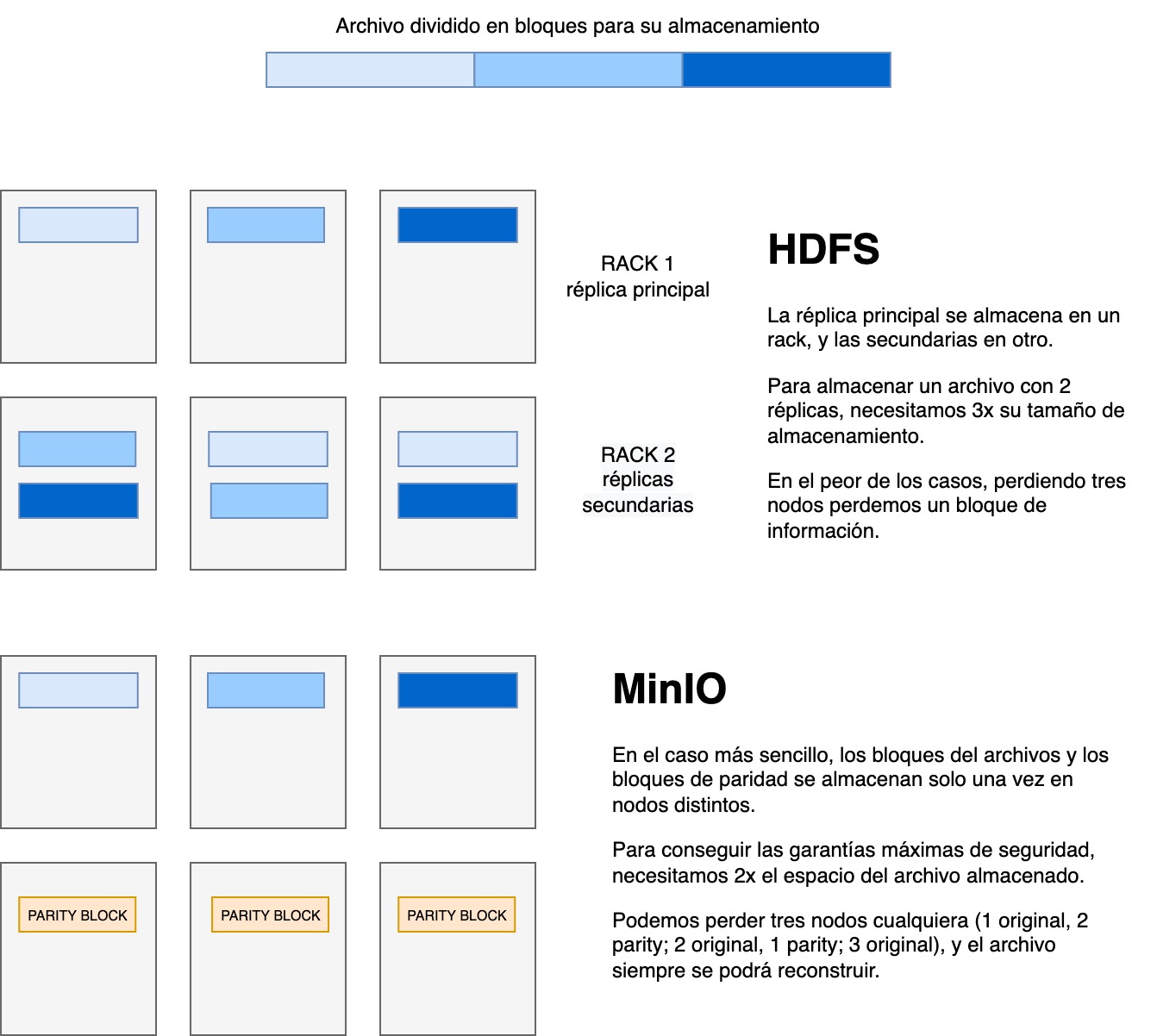
MinIO, en la línea de otros sistemas de almacenamiento distribuidos como HDFS de Hadoop, también se encarga de crear réplicas y versiones de todos los ficheros automáticamente. Sin embargo, el sistema de réplica es distinto al de HDFS. Mientras que este último simplemente hace una copia exacta de los datos y los ubica en un servidor distinto, MinIO utiliza una técnica llamada erasure coding para garantizar la recuperabilidad de los datos utilizando menos espacio.
¿Cómo funciona el erasure coding? Cada fichero se divide en M bloques más pequeños, que se almacenarán en servidores distintos. Además, se añaden K bloques de paridad, que son secuencias de bits que permiten recalcular los datos perdidos mediante series complejas de sumas y divisiones. La clave de los bloques de paridad es que funcionan sean cuales sean los bloques que se pierdan, siempre que dispongamos de K bloques (originales o de paridad). Por eso, como mucho, necesitaremos tantos bloques de paridad como bloques de datos. Esto significa que, con MinIO, utilizando menos espacio de disco las garantías de disponibilidad son mucho mayores.
Matar una mosca a cañonazos
En el panorama actual del Big Data, separar el hardware de almacenamiento de datos del hardware de procesamiento se está convirtiendo en el paradigma más aceptado. Esta división permite aprovechar al máximo los recursos disponibles, utilizando arquitecturas más eficientes y flexibles, así como software especializado para cada función. El almacenamiento de objetos se adapta como un guante a este nuevo paradigma, pero podríamos preguntarnos, ¿es adecuado para almacenar datos estructurados? Al fin y al cabo, no es una base de datos.
S3 o MinIO sí se usan para almacenar datos estructurados gracias a formatos columnares como Orc o Parquet, propios también del ecosistema Hadoop. En conjunción con el formato de tablas Iceberg, se pueden llevar a cabo consultas eficientes sobre petabytes de datos, y con garantías de corrección. En futuros posts profundizaremos en los formatos columnares y en Iceberg, pero lo que ahora nos concierne es el almacenamiento de objetos. ¿En qué casos no es recomendable su uso?
El almacenamiento de objetos brilla en la lectura intensiva de datos, pero no en la escritura y, sobre todo, no en la modificación de archivos. Las APIs de S3 o Minio funcionan mediante APIs REST, con verbos sencillos como list, put, get o delete, pero no proporcionan funcionalidades para modificar los archivos. Esto significa que cada alteración supone la reescritura del archivo completo. Además, tampoco permiten acceder a un subconjunto de los datos de forma directa (hay que leer todo el archivo). Por lo tanto, si nuestra aplicación va a requerir cambios frecuentes en los datos, o se utilizará para consultar filas concretas de una tabla, lo mejor será utilizar una base de datos relacional.
Por ello, además de MinIO como sistema de almacenamiento, nuestra plataforma de Big Data cuenta con una base de datos PostgreSQL. Por una parte, dará soporte a los casos de uso mencionados arriba. Pero, además, conviene tener en cuenta que la solución más sencilla y eficiente para un conjunto de datos de incluso cientos de millones de filas puede ser una base de datos a la antigua usanza.
Para finalizar
En esta entrada hemos puesto el primer ladrillo de la plataforma Big Data, sentando las bases del almacenamiento de datos estructurados y no estructurados. Si quieres ver cómo instalar las herramientas y algunos ejemplos de uso, pásate por nuestro repositorio de Github.