Utilizando el estándar OAuth2 de forma segura

El estándar OAuth2 es tan conocido como complejo. El hecho de que sea un estándar en evolución y el exceso de información disponible, hace que sea muy fácil encontrar artículos con información contradictoria o que se recomiende el uso de flujos que actualmente se consideran “legacy” por motivos de seguridad.
En este artículo, haremos un repaso de los flujos que componen OAuth2 y recomendaremos los flujos a utilizar para cubrir distintos escenarios. Pero antes, empecemos desde el principio.
¿Qué demonios es OAuth y por qué debería importarme?
Como estas cosas se entienden mejor con un ejemplo, vamos a ponernos en situación y pensar que queremos desarrollar una aplicación web que gestiona fotos. Como sabemos que muchos de nuestros usuarios potenciales utilizan Google Photos para almacenar y gestionar sus álbumes de fotos, vemos interesante que nuestra aplicación pueda conectarse con Google para obtener los álbumes del usuario que está utilizando nuestra aplicación. Investigamos un poco y vemos que Google ofrece una API para obtener el listado de álbumes de un usuario así que todo parece encajar a la perfección.
Evidentemente, el servicio de Google Photos no es público y requiere que el usuario final esté autenticado de alguna forma.
¿Cómo podemos conseguir esto?
Una opción podría ser que ese usuario introdujera sus credenciales de Google (usuario y password) en nuestra aplicación, de forma que nuestra aplicación pudiera autenticarse contra Google en nombre de ese usuario y de esta manera, obtener sus álbumes. Esto no tendría mucho sentido ya que estaríamos entregando a la aplicación la llave de nuestra cuenta de Google y además de los álbumes, podría acceder a todo tipo de información o realizar cualquier acción en nuestro nombre.
Necesitamos por tanto, un sistema que permita otorgar acceso a cierta información por parte de aplicaciones de terceros pero indicando explícitamente qué acciones se van a poder realizar en nuestro nombre y sin tener que entregar para ello nuestras crendenciales. El estándar OAuth nace precisamente para dar respuesta a esta necesidad. El primer borrador de OAuth fué publicado en 2007 y fué desarrollado principalmente por gente de Twitter y Google. En abril de 2010 se publicó la versión 1.0 del protocolo OAuth.
Retomando el ejemplo anterior, si implementásemos la aplicación de gestión de fotos utilizando OAuth, veríamos que cuando nuestra aplicación necesitase acceder a la API que devuelve el listado de álbumes que el usario en curso tiene en Google Photos, en lugar de pedir que el usuario introduzca las credenciales de Google en nuestra aplicación, se redirigiría a una pantalla de login gestionada por Google.
Una vez completada la autenticación, se le mostraría una pantalla en la que tendría que dar el cosentimiento explícito para que la aplicación pudiera consumir esa (y solo esa) información:
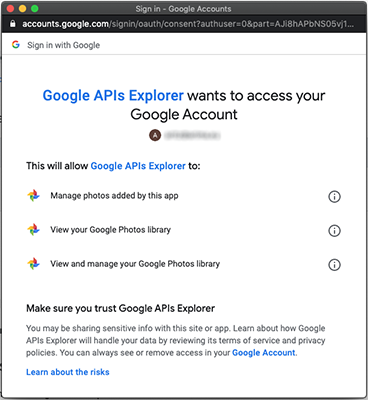
Tras el consentimiento del usuario, Google se encarga de devolver el control a la aplicación que inició el proceso proporcionándole un token con una fecha de caducidad. La aplicación podrá utilizar este token en las llamadas a las APIs que correspondan para acceder a la información para la que ha sido autorizado.
El problema de la primera versión de OAuth es que era complejo, estaba dirigido sobre todo a aplicaciones web y no era demasiado escalable. Para dar respuesta a estas limitaciones, en 2012 se publicó la versión 2.0 del protocolo OAuth junto con el estándar para el uso de “bearer tokens”. Se puede decir que OAuth2 es una reescritura del estándar ya que se aplicaron todas las lecciones aprendidas con la primera versión y esto a su vez les obligó a romper compatibilidad con la primera versión.
En el estándar OAuth2 se hace referencia a los siguientes roles que son los que participan en los distintos flujos disponibles:
- Resource Owner: Es el dueño de la información a la que se intenta acceder. En el ejemplo anterior, sería el usuario que está utilizando la aplicación y que es el dueño de las fotos de Google Photos a las que se intenta acceder.
- Client Application: Es la aplicación que pretende acceder al recurso protegido. En el ejemplo anterior, sería la aplicación que hemos desarrollado nosotros.
- Authorization Server: Es el servicio encargado de emitir tokens que permiten el acceso a un recurso protegido una vez que el dueño de dicho recurso haya otorgado su consentimiento. En el ejemplo anterior, el Authorization Server sería el servicio central de Google que se encarga de autorizar usuarios https://accounts.google.com.
- Resource Server: Se refiere al servicio que expone los recursos protegidos a los que se pretende acceder. En nuestro ejemplo, este papel correspondería al servicio Google Photos de Google.
Tal y como hemos apuntado, el objetivo de OAuth es impedir que el usuario tenga que introducir sus credenciales en aplicaciones de terceros para darles acceso a los recursos que pueda disponer en otras aplicaciones. Para conseguir esto, se realiza un proceso de autorización en el que intervienen los distintos actores implicados (“Resource Owner”, “Client Application” y “Authorization Server”) cuyo resultado es un token con el que la aplicación puede invocar las APIs que dan acceso a los recursos protegidos. Existen distintas variaciones de este flujo para adecuarse a diferentes escenarios:
Authorization code grant
Se podría decir que este es el flujo OAuth2 principal y el que se debería utilizar en todos los casos en los que sea posible. Este flujo se puede utilizar cuando tenemos una aplicación en la que la lógica de presentación se lleva principalmente en el servidor, es decir, el servidor es el encargado de renderizar los HTML. A continuación se especifican los pasos que se llevan a cabo en este flujo:
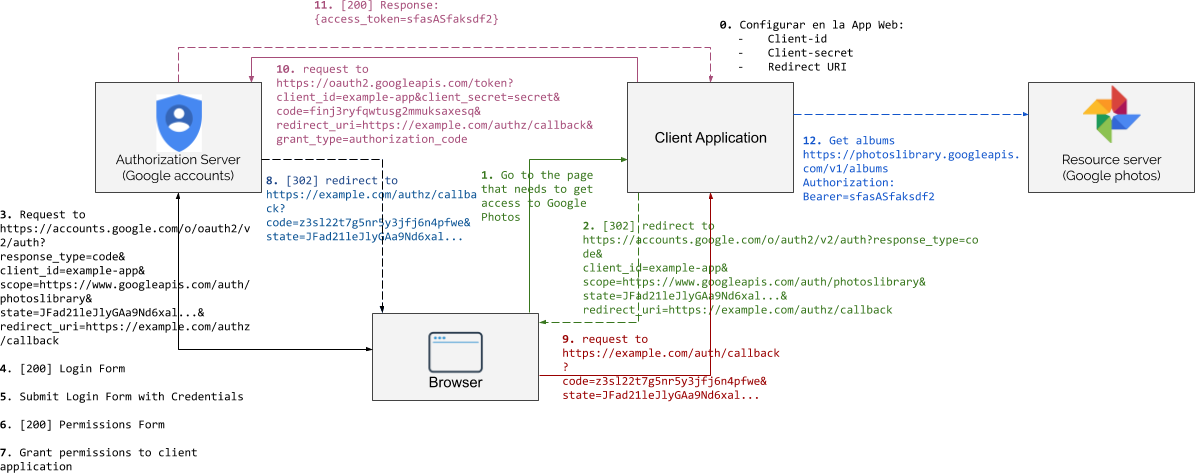
0. Hay un proceso previo en el que se registra la aplicación cliente en el “Authorization Server”. Para llevar a cabo este registro, hay que indicar el client-id, el client-secret y redirect-uri de la aplicación que se está registrando. Normalmente los “Authorizations Servers” permiten registrar varias URIs de redirección. En el caso de Google, este registro se lleva a cabo en el portal de desarrolladores (más info aquí).
1. y 2. Cuando el usuario intenta acceder a una parte de la aplicación que necesita poder acceder a su cuenta de Google Photos, se iniciará el flujo OAuth2. El objetivo de este flujo es que el usuario pueda dar su consentimiento a que la aplicación acceda a información de Google Photos en su nombre. Para ello, forzará una redirección del navegador a la URL de autenticación que expone el “Authorization Server” pasándole los siguientes parámetros en la URL como “query string”:
- response_type: El valor de este parámetro indica el tipo de flujo que queremos iniciar. En este caso será
codeya que es el valor correspondiente al “Authorization Code Grant”. - client_id: El identificador del cliente que está iniciando el flujo.
- scope: En esta propiedad se indica a qué recursos del usuario pretende acceder la aplicación pudiendo establecerse más de un scope. En el ejemplo se ha utilizado
https://www.googleapis.com/auth/photoslibraryque según la documentación es uno de los scopes que permiten acceder a los álbumes de un usuario. - redirect_uri: La URI a la que el “Authorization Server” tiene que redirigir una vez que el usuario haya otorgado su consentimiento. Esta URI tiene que coincidir con alguna de las URI que se ha registrado para la aplicación.
- state: Se trata de un valor que la aplicación cliente utiliza para mantener un estado entre la petición que inició el flujo y la respuesta que llega en el callback. El “Authorization Server” incluye este valor en la petición que devuelve el control a la aplicación que inició el flujo OAuth. Este parámetro también se puede utilizar como mecanismo de defensa ante ataques CSRF (“Cross Site Request Forguery”) tal y como se indica en el RFC6749.
3. ,4. y 5. El usuario llega a la pantalla de login del “Authorization Server” (Google Accounts en el caso de google) e introduce sus credenciales.
6. y 7. Una vez validadas las credenciales, el “Authorization Server” muestra una pantalla en la que se le enumeran los accesos o scopes que la aplicación cliente está solicitando. En este caso, se pediría permiso para poder acceder a los álbumes de fotos.
8. y 9. El usuario da su consentimiento para que la aplicación cliente pueda acceder a la información solicitada y esto provoca una redirección a la url redirect_uri que se había enviado al iniciar el flujo. En esta URL, se añadirá como parámetro un code y el state cuyo valor tendrá que ser el mismo que la aplicación cliente envió al iniciar el flujo.
10. y 11. La aplicación cliente obtiene el code de la URL e intercambia este code por un access_token haciendo una petición POST al endpoint que el “Authorization Server” habrá dispuesto para tal efecto (en el caso de Google https://oauth2.googleapis.com/token). Además del code, también es necesario que la aplicación cliente envíe su client_id y su client_secret en el cuerpo de la petición.
12. La aplicación cliente puede utilizar el access_token que ha recibido para obtener los álbumes que el usuario tiene alojados en Google Photos. Para conseguir esta información puede hacer peticiones al servicio https://www.googleapis.com/auth/photoslibrary enviando el access_token en la cabecera HTTP “Authorization: Bearer” tal y como se indica en la especificación.
El último paso consistiría en que el “Resource Server” validase el access_token antes de devolver la información protegida. La forma en la que se lleve a cabo esta validación dependerá principalmente de la naturaleza del token ya que los “Authorization Server” normalmente pueden enviar dos tipos de tokens:
-
JWTs firmados: Un JWT es un string con formato JSON que está firmado y codificado siguiendo los criterios especificados en la RFC 7519. El hecho de que el contenido del JWT esté firmado, hace que se pueda verificar la validez del mismo sin tener que hacer ninguna llamada remota. Por lo tanto, si el resource server recibe un token de este tipo, puede verificarlo y devolver directamente la información solicitada.
Los JWTs tienen una propiedad (
exp) en la que se indica la fecha de expiración del mismo. Por lo tanto, el resource server tendrá que verificar también que el JWT no esté caducado.Utilizar JWTs como tokens de acceso es una práctica bastante habitual. El objetivo de utilizar este tipo de tokens autocontenidos suele ser evitar el tener que hacer peticiones adicionales al “Authorization Server” para verificar si el token es válido. De esta forma, el token será válido mientras no se alcance su fecha de expiración.
Sin embargo, ¿qué ocurre en caso de que el
access_tokense revoque por cualquier motivo? Desde el panel de administración de Google por ejemplo, un usuario puede quitar en cualquier momento los permisos que ha otorgado a una aplicación determinada. Esto provoca que todos losaccess_tokenyrefresh_tokenque se hubieran expedido para esa aplicación sean revocados de inmediato.En este escenario, lo que ocurriría es que el “Resource Server” no sería consciente de esta revocación porque lo único que hace es validar que esté correctamente firmado y que la fecha de expiración que contiene no haya vencido. En definitiva, seguiría aceptando el token revocado hasta que este caducase. Este es uno de los motivos por los que no se aconseja utilizar JWTs como
access_token. -
Tokens Opacos: Al contrario que los JWT, los tokens opacos no contienen ningún tipo de información legible para el cliente y por este motivo, pueden ser una secuencia de caracterés pseudoaleatorios. Este hecho hace que el “Authorization Server” tenga que mantener un registro de los
access_tokenque ha expedido y que tenga que exponer un endpoint al que el “Resource Server” pueda hacer peticiones para verificar la validez de los token que recibe. A este proceso de validación se le llama introspección y está especificado en la RFC 7662.La recomendación es utilizar este tipo de tokens como
access_tokeny hacer verificaciones utilizando el endpoint de introspección.
Los access_token suelen tener una fecha de expiración muy cercana en el tiempo (por debajo de una hora) para que si este se ve comprometido, solo pueda explotarse durante un corto periodo de tiempo. Esto que en un principio suena lógico tiene un inconveniente:
¿Qué ocurre cuando el access_token que una aplicación ha obtenido legitimamente caduca? ¿Hay que volver a iniciar el flujo OAuth pidiendo el consentimiento del usuario final? Esto no parece muy usable en la mayoría de casos.
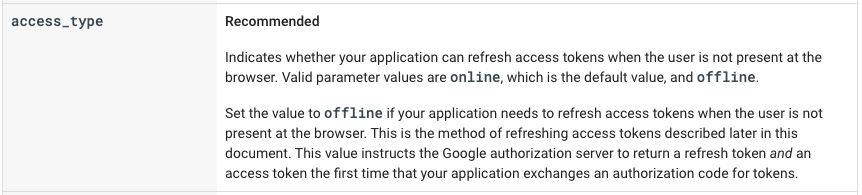
Para dar respuesta a esta problemática, en la especificación OAuth2 se recoge la posibilidad de obtener nuevos access_token utilizando un flujo de refresco. Para ejecutar este proceso de refresco, es necesario haber obtenido previamente un token adicional denominado refresh_token. Este token viene junto con el access_token en el paso 11) del diagrama anterior siempre y cuando se hayan dado las condiciones para ello. En el caso de Google por ejemplo, la condición para que devuelva un refresh_token es que en la petición que inicia el flujo se añada el parámetro access_type con el valor offline. Este es el apartado de la documentación en el que se hace referencia a este parámetro:
Tal y como se ha comentado, el “Authorization Code Grant” es el flujo recomendado para la mayoría de casos pero tiene un requisito que no todas las aplicaciónes pueden cumplir: necesita poder almacenar un client_secret de forma segura ya que este valor es necesario para hacer el intercambio del code por el access_token en el paso 10) del proceso.
Hay aplicaciones que por su naturaleza no pueden almacenar secretos sin que estos se vean fácilmente comprometidos. Dos ejemplos claros de este tipo de aplicaciones serían:
-
Las aplicaciones cuya lógica de presentación se ejecuta integramente en el navegador haciendo uso de Javascript (también conocidas como single page applications o SPAs).
-
Aplicaciones móviles nativas.
Decimos que este tipo de aplicaciones no pueden almacenar secretos porque el código es fácilmente accesible por el usuario final. En el caso de las aplicaciones SPA por ejemplo, es suficiente con abrir las herramientas de desarrollador e inspeccionar el código fuente o analizar las peticiones que se hacen al servidor para obtener el secreto. Se puede aplicar prácticamente lo mismo para las aplicaciones móviles nativas aunque el esfuerzo necesario para poder lograr esta información sea un poco mayor.
Es en este punto cuando los desarrolladores empezamos a dirigir nuestra atención hacia otros flujos que también se contemplan en la especificación como pueden ser el “Resource Owner Password Credentials Grant” y el “Implicit Grant”.
Resource owner password credentials grant
En este flujo, se utilizan directamente las credenciales del resource owner como forma de autorización para obtener un token. Este sería el diagrama del flujo:
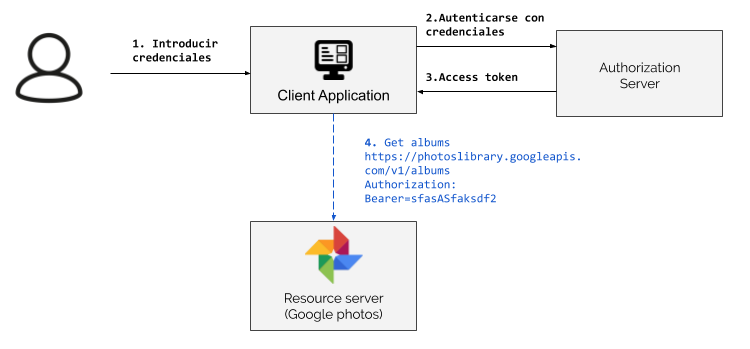
Como se puede ver en el diagrama, en este flujo el usuario introduce sus credenciales directamente en la aplicación cliente para que haciendo uso de estas credenciales, la aplicación pueda solicitar tokens de acceso al “Authorization Server”.
Un momento…
¿No habíamos dicho que con OAuth precisamente se busca evitar el tener que introducir las credenciales en aplicaciones de terceros?
Efectivamente y es por eso que en la especificación se indica lo siguiente:
The credentials should only be used when there is a high degree of trust between the resource owner and the client (e.g., the client is part of the device operating system or a highly privileged application), and when other authorization grant types are not available (such as an authorization code).
Es decir, dicen que solo se debe utilizar este flujo en aplicaciones que son de un alto nivel de confianza y cuando no se puede utilizar ningún otro flujo. A pesar de esto, en la práctica la recomendación es no utilizar este flujo en ningún caso. Los motivos principales por los que utilizar este flujo se considera mala práctica son los siguientes:
-
Se fomentan malos hábitos de los usuarios ya que este flujo es muy parecido a un ataque de “phishing”: se le presenta un formulario al usuario en el que se le pide que introduzca sus credenciales de otra aplicación como puede ser Google en lugar de redirigirle a la pantalla de autenticación de esa aplicación.
El usuario debería acostumbrarse a únicamente introducir sus credenciales en la pantalla de login de la plataforma y desconfiar si cualquier otra aplicación le pide que las introduzca.
Google por ejemplo, utiliza una pantalla central para gestionar la autenticación y es la misma tanto para sus propios productos (Gmail, Google Calendar, Drive,…) como para las integraciones con terceros.
-
Las credenciales de un usuario son información altamente sensible. Por lo tanto, es preferible que sean manejadas por el menor número de aplicaciones posible con el objetivo de reducir las probabilidades de que pueda haber fugas de información tanto de manera malintencionada como por accidente (vía logs, etc.).
-
En el flujo “Resource Owner Password Credentials Grant” el usuario introduce sus credenciales pero no tiene el control sobre qué uso se va a hacer de los mismos. Al explicar el “Authorization Code Grant” se ha visto como el “Authorization Server” se encarga de mostrar una pantalla de consentimiento al usuario para autorizar que la aplicación pueda realizar una serie de acciones (scopes) en su nombre. Por el contrario, en el “Resource Owner Password Credentials Grant”, una vez que la aplicación dispone de las credenciales, puede establecer los scopes que considere oportunos sin el consentimiento del usuario.
Debido a estas problemáticas y otras que no se han recogido en este artículo, este flujo no está soportado por Google y muchos otros Authorization Servers.
Implicit grant
Este es el flujo que se ha venido recomendando para aplicaciones móviles y SPAs hasta hace no demasiado tiempo. El diagrama de este flujo es el siguiente:
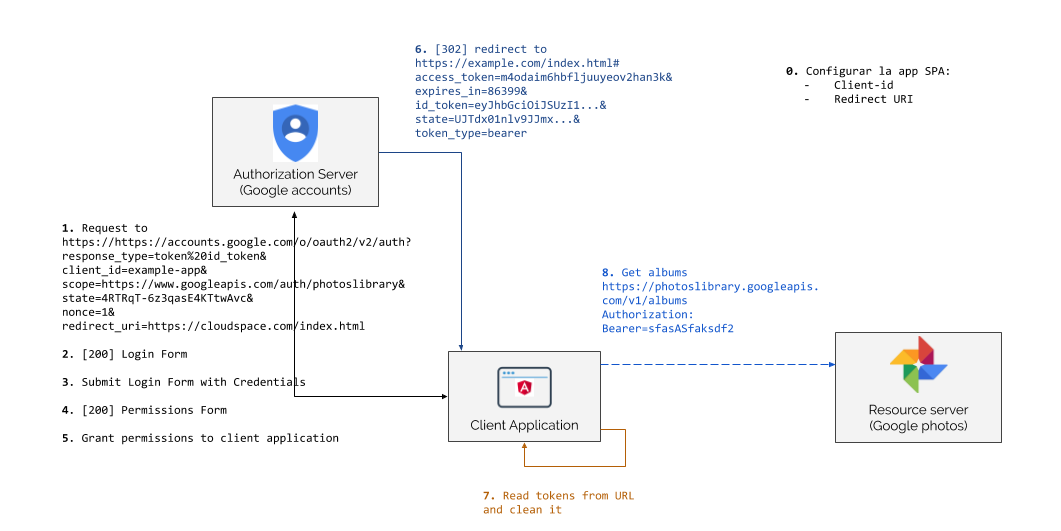
Este flujo es una versión simplificada del “Authorization Code Grant”. En la primera petición se envía el response_type con valor a token para indicarle al “Authorization Server” que se va a usar el flujo “Implicit Grant”. La diferencia con el “Authorization Code Grant” es que una vez el usuario final se autentica y otorga su consentimiento, el “Authorization Server” hace la redirección al redirect_uri pasándole el access_token directamente como parte de la URL. Es decir, no existen los pasos 10) y 11) del flujo “Authorization Code Grant” en el que se obtiene un code temporal que hay que intercambiar por un access_token haciendo uso del client_secret.
Gracias a esto, no es necesario disponer de un client_secret para llevar a cabo este flujo y por lo tanto, el flujo se puede utilizar en aplicaciones que no pueden almacenar secretos de forma segura.
Todo esto suena muy bien pero si el “Implicit Grant” es más simple que el “Authorization Code Grant” y además no necesita secretos, ¿por qué no lo utilizamos en todos los casos?
Buena pregunta…
El caso es que este flujo tiene sus inconvenientes tal y como se recoge en la RFC6819:
Riesgo de interceptar el access_token
Tal y como se ha explicado, el access_token viene como parte de la URL que hace la redirección hacia la aplicación cliente y no en el cuerpo de la respuesta de una petición POST como ocurre en flujo “Authorization Code Grant”. Este detalle es muy importante ya que al venir el token en la URL, este puede quedar registrado en logs o históricos. Por lo tanto, cualquiera con acceso a este tipo de información en la aplicación cliente podría obtener el access_token y explotarlo de manera ilegítima.
Para mitigar este problema, en lugar de utilizar un “query string” para pasar este valor, se utiliza un fragmento o hash. Si nos fijamos en la URL del paso 6) del diagrama, podemos ver cómo el access_token se envía como fragmento haciendo uso del caracter #: https://…index.html#access_token=m4odaim6h…
Los navegadores, no envían la parte del fragmento al servidor. Esto quiere decir que cuando el navegador haga la petición a index.html para descargarse la aplicación SPA, no enviará todo lo que sigue al caracter #. De esta forma, se consigue limitar la superficie de un posible ataque ya que sabremos que el access_token no quedará registrado en los logs del servidor en el que se aloja la aplicación cliente. Sin embargo, el fragmento sí que quedaría almacenado en el histórico del navegador.
En este RFC, se enumeran esta y otras amenazas relacionadas. Incluso en la propia especificación OAuth2 se alerta de las implicaciones de seguridad que tiene utilizar el flujo “Implicit Grant”:
Implicit grants improve the responsiveness and efficiency of some clients (such as a client implemented as an in-browser application), since it reduces the number of round trips required to obtain an access token. However, this convenience should be weighed against the security implications of using implicit grants, such as those described in Sections 10.3 and 10.16, especially when the authorization code grant type is available.
No permite el uso de refresh_token
En el punto anterior se ha comentado que la forma en la que las aplicaciones cliente obtienen el access_token cuando se utiliza “Implicit Grant” no es demasiado seguro. Si bien es cierto que las consecuencias de una fuga de access_token son limitadas porque los access_token expiran en un periodo de tiempo muy corto, no se podría decir lo mismo de un refresh_token.
Los refresh_token tienen un ciclo de vida mucho más largo ya que se utilizan para obtener nuevos access_token sin necesidad de que el usuario final tenga que estar dando su consentimiento continuamente. En el caso de Google por ejemplo, el refresh_token caduca cuando no haya sido utilizado durante 6 meses. Por lo tanto, la fuga de un refresh_token sería catastrófico ya que podría utilizarse para generar access_token durante un largo periodo de tiempo. Es por esto que la propia especificación de OAuth2 advierte que la expedición de tokens de refresco no está soportada cuando se utiliza “Implicit Grant”.
Como ya hemos dicho, el no poder utilizar tokens de refresco atenta contra la usabilidad ya que cada vez que el access_token caduque, tendremos que volver a iniciar el flujo y redirigir al usuario al “Authorization Server” para que vuelva a dar su consentimiento. Para dar respuesta a este problema, existe el concepto de “Silent Refresh” que consiste en utilizar un IFrame para obtener nuevos access_tokens de forma silenciosa. Este “hack” tiene varios condicionantes y riesgos que no se van a extender en este artículo. Se puede leer más información sobre cómo efectuar un “silent refresh” aquí.
Si no recomendamos utilizar ni “Resource Owner Password Credentials Grant” ni “Implicit Grant” para nuestras aplicaciones móviles o SPAs, ¿qué otras opciones tenemos? La respuesta a esta pregunta es…
Authorization Code Grant with PKCE
El flujo “Authorization Code Grant with PKCE” nació para dar respuesta a todos los problemas asociados a las aplicaciones públicas (SPAs y móviles) ya que se trata de una extensión de “Authorization Code Grant” dirigido a este tipo de aplicaciones. Las motivaciones y particularidades de este flujo se recogen en la RFC 7636 y este es su diagrama correspondiente:
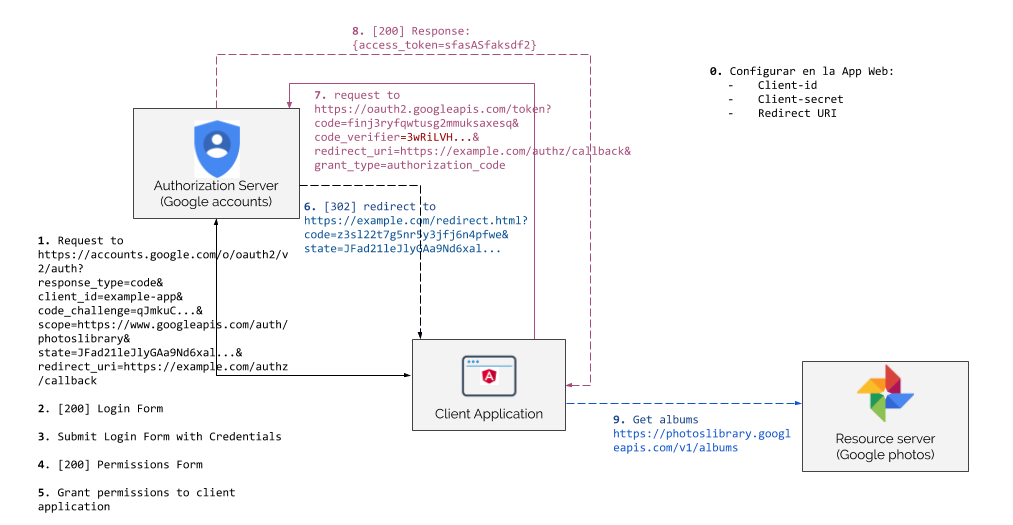
Tal y como se puede ver en el diagrama, el flujo es idéntico a un “Authorization Code Grant” solo que en el paso 1) se añade un parámetro extra llamado code_challenge y en el paso 7) en lugar de enviar el client_secret se envía otro parámetro denominado code_verifier. Es decir, la combinación de code_challenge + code_verifier sustituyen al client_secret creando una especie de secreto temporal y único por cada flujo.
¿Cómo funciona esto?
Al inicio del flujo, la aplicación cliente genera un code_verifier que no es más que un string aleatorio criptográfico que tiene que cumplir una serie de condiciones. A continuación, se crea el code_challenge que es un derivado del code_verifier. Hay múltiples formas de generar el code_challenge pero la recomendación es utilizar SHA-256 aplicando una fórmula del estilo code_challenge = BASE64URL-ENCODE(SHA256(ASCII(code_verifier))). La forma en la que se hace la verificación de este “challenge” es la siguiente:
-
En el primer paso del flujo, la aplicación cliente guarda el
code_verifiery envía elcode_challengeal “Authorization Server”. -
El “Authorization Server” almacena el
code_challengerecibido y una vez que el usuario da su consentimiento, responde con elcode. -
Cuando la aplicación cliente va a intercambiar el
codepor elaccess_tokenen el paso 7), envía también elcode_verifierque había guardado previamente y que es el origen desde el que se había creado elcode_challengeenviado en el primer paso. -
Por último, el “Authorization Server” aplica la fórmula de derivación sobre este
code_verifiery lo compara con elcode_challengeque había guardado en el primer paso. Si los códigos son iguales, la petición es válida y devuelve elaccess_tokeny opcionalmente elrefresh_token. Los criterios que sigue el “Authorization Server” para devolver o no unrefresh_tokenson los mismos que en el “Authorization Code Grant”.
Por lo tanto, este flujo tienes las ventajas del “Authorization Code Grant” y puede utilizarse sin necesidad de disponer de un secreto “estático” ya que este se genera en caliente cada vez que se inicia un nuevo flujo.
Conclusiones
En este artículo se ha hecho una introducción a OAuth en el que se han explicado cuáles fueron las motivaciones para su creación así como la forma en la que funciona.
Se han repasado los principales flujos que se contemplan en la especificación para permitir a un usuario dar autorización a aplicaciones de terceros con el objetivo de que puedan realizar acciones en su nombre.
Si bien para aplicaciones web tradicionales en las que el renderizado de los HTML se realiza en servidor el flujo a utilizar está muy claro (Authorization Code Grant), cuando tratamos de buscar el flujo a utilizar para SPAs o aplicaciones móviles la información disponible es bastante confusa.
Debido a la evolución de la especificación o a la ambigüedad del propio texto, es fácil encontrar en internet artículos o comentarios en los que se invita a utilizar flujos que son potencialmente peligrosos como pueden ser “Resource Owner Password Grant” o “Implicit Grant”. La recomendación es que para este tipo de aplicaciones se utilice el flujo “Authorization Code Grant with PKCE” que salva la problemática de los secretos haciendo uso de criptografía.
En este artículo se han dejado a un lado los flujos en los que no interviene el usuario como puede ser el “Client Credentials Grant” u otros en los que no se utiliza un navegador como el “Device Authorization Grant”. De igual forma, se ha hablado solo de autorización que es lo que cubre OAuth y dejado a un lado la autenticación. Quizás tratemos estos temas relacionados en futuras publicaciones.
Por último, se ha visto que OAuth no es un protocolo sencillo de implementar y por lo tanto se recomienda utilizar librerías ya existentes que encapsulen toda esta complejidad.