Funciones con AWS Lambda

Recientemente, la palabra serverless está más y más presente en posts, foros, o cualquier recurso relacionado con el software. Por si no sabes lo que es, serverless implica despreocuparnos por la máquina donde se ejecuta nuestra aplicación y trivializa su despliegue. Es un concepto que tiene su miga, así que profundizaremos en él en otro post más adelante.
En este post en concreto quiero hablar de AWS Lambda, la solución serverless en forma de funciones (FaaS) que nos provee AWS. Una función se puede ver como cualquier aplicación que se active mediante un evento y realice cierta tarea.
AWS Lambda se encarga de:
- Levantar nuestra aplicación únicamente cuando se dispare el evento, y de matarla al poco tiempo de acabar la ejecución. Esto incluye provisionar una máquina para que se encargue de la ejecución, y lo hace todo en tiempo récord. Más adelante veremos algún ejemplo.
- Cobrarnos únicamente por el tiempo de ejecución de la función, minimizando al mínimo los costes y optimizando el uso de recursos.
- Levantar instancias de la aplicación de manera concurrente en caso de que sean necesarias. Con esto conseguiremos que nuestra función se adapte a picos de tráfico y tener la seguridad de que vamos a pagar solo por lo que utilizamos ¡Adiós a las máquinas que no trabajan y a quedarnos sin recursos!
Cómo funciona
Como ya hemos comentado, la función se dispara por la llegada de un evento. En el caso de Lambda, un evento puede venir porque:
- Se haya generado desde un recurso de AWS.
- Se haya generado en un recurso externo a AWS, como una cola Kafka.
- Se haya hecho una petición HTTP.
- Otros.
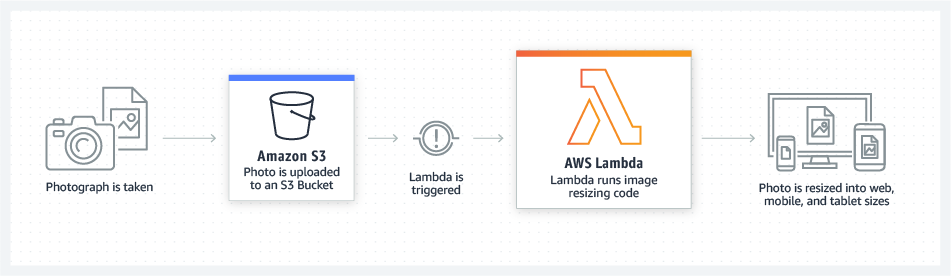
Para que nuestra aplicación pueda tratar el evento que llega desde AWS, lo primero que hay que hacer es utilizar el SDK que provee Amazon (o una librería compatible con Lambda como Spring Cloud Function) para implementar un handler que se encargue del evento.
En este post usaré una aplicación Spring Boot y con el SDK de AWS. Se puede ver el código de esta aplicación en este repositorio. El repositorio también contiene instrucciones sobre cómo crear la función.
Lambda nos da la opción de configurar en mayor detalle la función, pudiendo elegir la cantidad de memoria que queremos utilizar por instancia, el tiempo máximo de ejecución, definir variables de entorno para nuestra aplicación (desde aquí se pueden configurar propiedades de la JVM, por ejemplo), etc.
Una vez hecho esto, la función está lista para ser usada. Quiero recalcar que no hemos tenido que seleccionar un sistema operativo para la máquina, configurarla para que soporte la ejecución de aplicaciones Java o securizarla de ninguna manera. No me tengo que encargar de monitorizar el estado de ninguna máquina ni de establecer ningún sistema de autoescalado por si fuese necesario. Lambda se encarga de todo esto por nosotros.
En la siguiente imagen podemos observar los resultados de la ejecución de la función. A la izquierda se muestran los resultados de la primera ejecución o inicio en frío (cold-startup), y a la derecha los de la segunda ejecución o inicio en caliente (warm-startup). Podemos observar que hay una gran diferencia en el tiempo de ejecución, que sería aún más notable si nuestra aplicación tardase más en iniciarse por primera vez (por ejempo, si tuviese que crear un pool de conexiones con una base de datos).

El problema del cold-startup es común en serverless, ya que estamos constantemente levantando nuevas instancias. En un futuro post estudiaremos maneras de evitarlo. De momento, mencionaré que Lambda ofrece una opción llamada provisioned concurrency, que nos permite mantener activas el número de instancias que elijamos (pagando por ellas, claro).
Consideraciones:
Al leer sobre este servicio de AWS me he encontrado con ciertas limitaciones técnicas que me parecen importantes para tener en cuenta.
- La función debe ser paralelizable. Si llega una petición mientras ya hay otra siendo atendida por la instancia de nuestra función, se levanta otra nueva instancia. Esto implica que debemos asegurarnos de que no existen problemas de concurrencias al ejecutar la función simultáneamente. Un ejemplo podría ser una función que actualiza un registro de una base de datos.
- Existe un límite de memoria para asignar a la función de 10GB. Además, el número de vCPUs que se asigna es proporcional a la memoria escogida (máximo 6 vCPUs). Esto puede forzar a sobreprovisionar uno de los dos recursos, o incluso que no sean suficientes, ya que no son límites muy altos.
- Amazon nos deja elegir entre varios entornos de ejecución para la mayoría de lenguajes principales. Si estos no nos sirven (porque nuestro lenguaje no está o porque necesitamos una versión específica), es posible configurar uno personalizado o utilizar una imagen para que se lance un contenedor (hablaremos sobre esta opción en otro post).
- El tiempo máximo por ejecución son 15 minutos. Si esto no es suficiente para nuestro negocio o la función está mucho tiempo ejecutándose (tiempo facturable), puede que estemos más interesados en otro tipo de serverless.
Conclusiones
AWS Lambda es un servicio potente que se integra muy bien con el resto del entorno de AWS. Nos introduce al mundo serverles y todas sus ventajas, y hace que el despliegue de una aplicación sea más sencillo y barato que nunca.
Sin embargo, no es la solución a todos los problemas. Como siempre, cada caso en concreto tiene sus detalles y habrá que hacer un estudio para ver si Lambda encaja o si es mejor una solucion más tradicional. Lambda puede resultar muy caro si hay muchas peticiones simultáneas y de manera constante. En cualquier caso, a mí personalmente me ha servido para abrirme los ojos e introducirme a las funciones FaaS y me ha hecho replantearme algunas decisiones que he tomado en el pasado.